Have you ever wondered why we have so many different architectures for machine learning models? This is especially prevalent in the field of computer vision, for instance, in image classification we have resnets, ViTs, and a whole litany of slight modifications of the above 2. While in object detection, we have YOLO, SSD, DETR, R-CNNs, and so much more. What sets apart these architectures, and why can’t we just have one major architecture that just works?
This is where the concept of inductive biases comes in. I believe the major thing setting apart the commonly used architectures, is the levels of inductive biases they have. Understanding how inductive biases are introduced, is also critical to understanding modern deep learning in general. It allows you to draw connections between seemingly unrelated architectures, and select the best ones for your own uses cases. So, what even are inductive biases?
What are inductive biases?
The simplest way to explain inductive biases, is that they are assumptions our model architecture (or possibly even our training method, as will be discussed later) makes about the data. And what does this mean? Well, let us take the example of resnets and ViTs.
As we know, ViTs often have superior performance compared to resnets, but they take a significantly longer time to hit the same performance of resnet (for instance, ViT converges to 95% accuracy while resnet can only converge to 90%, but to hit 85%, ViT takes 10 hour of training while resnet only takes 1 hour). This all boils down to the inductive biases present within resnets!
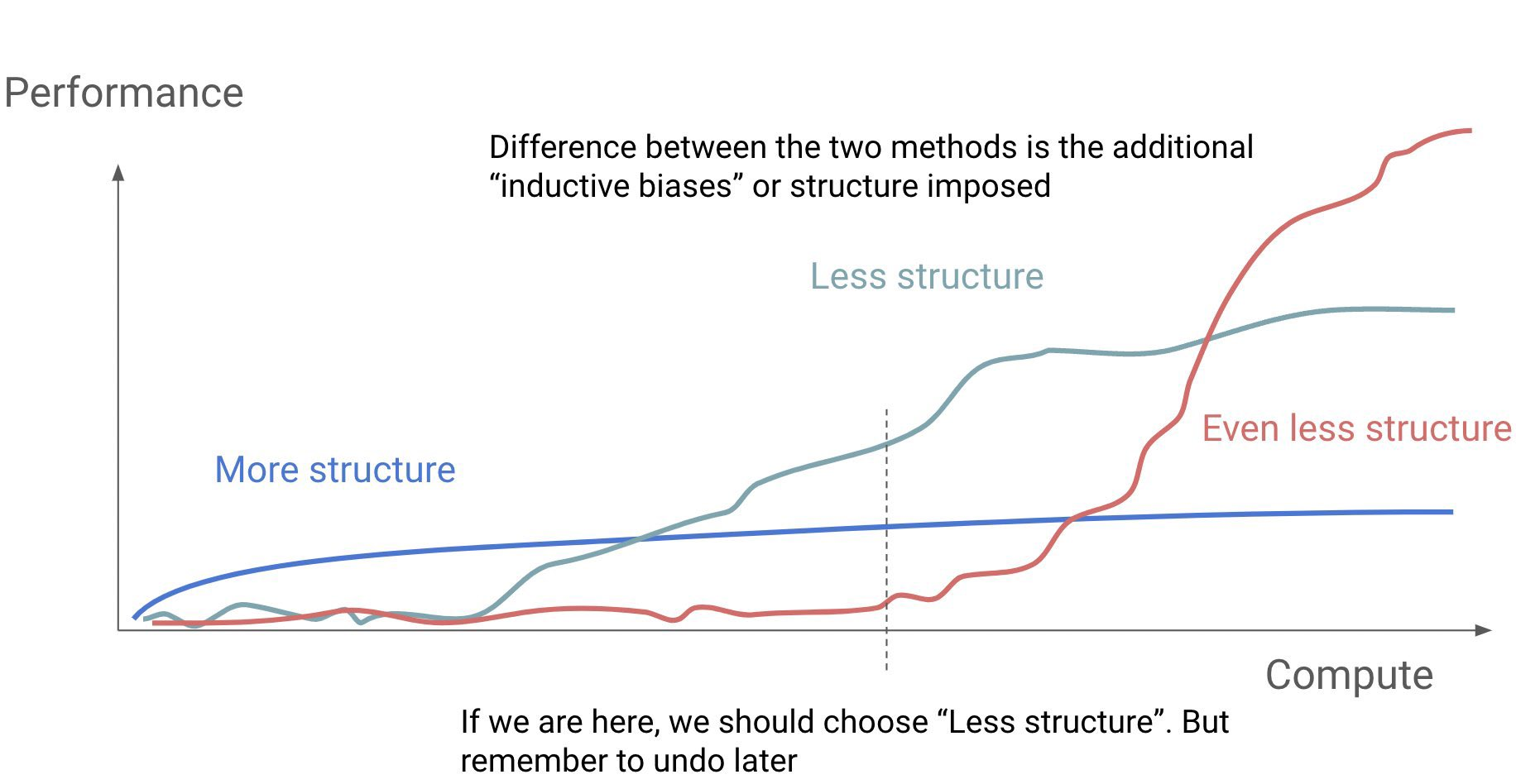
In essence, resnets are an example of the “more structure” models in the above infographic, while ViTs are the “less structure”. The structure of resnets comes with the implicit assumption that details that are near in proximity to one another have strong relations, which comes with the design of convolutions (which only take vicinal pixels into account when doing the scan). Meanwhile, ViTs allow all parts of the image to attend to one another, allowing for a far more global understanding of context, while having reduced inductive biases. However, it is due to this much larger access to information, that causes ViTs to have massively increased training times as compared to resnets.
Interpretation
We can interpret inductive biases as reducing the degrees of freedom the network has available. We effectively constrain the solution space to something much smaller than that of a model with lesser inductive biases. This can be interpreted in the sense that, the average distance between a random set of parameters and a minima is much higher for ViTs than resnets.
But as ViTs have a wider solution space and more degrees of freedom, the solution the model converges to would also be superior, as while the inductive biases of resnets are very good abstractions, they still are abstractions.
To make an analogy, while C (let us ignore inline assembly) allows one to write a great many programs, the set of all the programs that can be written in C is a subset of all programs that can be written in assembly. While assembly takes much longer to write than C, the best solution to a problem written in assembly would pretty much always outperform the best solution written in C (see: ffmpeg codebase).
Applications
So, why should one even care for inductive biases? I feel inductive biases allow one to effectively draw connections between many modern architectures, and better understand how many performance boosts are obtained. This may even extend to training methods! Let’s have another example - https://arxiv.org/abs/2501.04765v2, this is the paper that inspired me to write this blog post in the first place, do take a look.
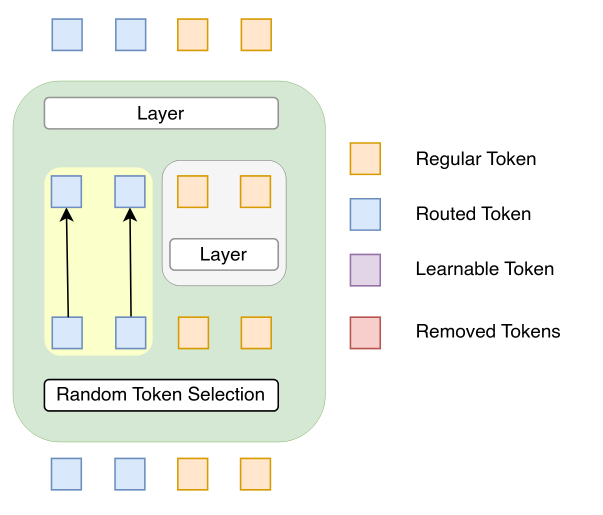
Simply put, this paper proposes a method to significantly decrease training time of diffusion transformers, by randomly selecting a fraction of the tokens to skip some layers. This reduces the training time significantly, orders of magnitude faster than without this technique. So, what inductive biases are introduced?
Please take some time to ponder before continuing.
If we think about it, the bias introduced is actually remarkably similar to those introduced by latent diffusion models. Simply put, we assume a low density of information in images, and that if we already have a low resolution version of an image, we can upscale it relatively trivially with few model layers. This leads to the likely trade-off that the model will be less capable when it comes to fine details, for instance, hands (which has been a notorious weakness of most image generation models up till very recently, as most models perform diffusion in a lower dimensional latent space).
By analyzing inductive biases introduced, we are able to effectively link two weakly related model designs, and see how one is just the other expressed at the training level instead of the architecture level. Arguably, this training method should outperform the standard latent diffusion model, as it is less rigidly built, and the random token bypass is also a very strong form of regularization, allowing the model to form many internal ensembles.
Conclusion
A strong comprehension of inductive biases is critical for effective understanding of modern neural network design. Oftentimes, when reading new papers, I try to think about the inductive biases present, and what exactly is the trade-off we are making when we use it. I would recommend that anyone interested in gaining a more solid foundation in machine learning, try their hand at spotting the inductive biases of various architectures and designs, for the world of machine learning really is quite beautifully interlinked, if you can see it.